2024/03/29


株式会社サイバーエージェントのアカウントプランナーとして数々の国内⼤⼿企業のデジタルマーケティング戦略⽀援に携わった後、2016年に現在の株式会社S-fleaegを創業。デジタルマーケティング領域は10年以上のキャリア。京都⼤学⼤学院 経営学修士(MBA )取得。同志社大学大学院 商学研究科博士課程 在学。⽇本マーケティング学会 会員。研究の専門分野はマーケティング。
Googleは、インターネット上の情報を自動的に収集するプログラムである「クローラー」によって、日々、信頼性あるウェブページをランキング形式にして表示するための活動をしています。
このクローラーとは何か、ウェブサイトの検索結果にクローラーがどのように影響しているのか、またSEO対策と関連性があるのか、SEO担当者は理解しておかなければなりません。
この記事では、クローラーの役割から制御方法までを包括的に解説します。
目次
クローラーとは、ウェブ上の情報を自動的に収集するためのプログラムのことを指します。
これは、検索エンジンがウェブ上の情報を収集し、その情報をもとに検索結果を生成するための重要なプロセスの一部です。
ウェブスパイダー、ボット、インデクサーと呼ばれることもありますが、全て同じ意味で用いられます。
クローラーとその働きを理解することは、ウェブサイトのSEO対策を行う上で非常に重要なものとなります。
クローラーが、ネット上でウェブページを見つけ(検出)、情報を収集し、リンクを辿って別のウェブページに移動し、さらに情報収集を行う一連のプロセスを「クローリング」と呼びます。
収集した情報は、検索エンジンのデータベースに格納、つまりインデックス登録され、検索クエリに対して、最適な情報を検索結果として返します。
つまり、検索結果に表示されるためには、ウェブサイトがクローリングされ、インデックスに登録されなければなりません。
クローリングを、単に「巡回」と表現することもありますが、巡回のためのクローラーは目的によって複数の種類が存在します。
クローラーには複数の種類がありますが、最も一般的なクローラーは、Googleのウェブクローラーである「Googlebot(ボット)」で、スマートフォン、パソコン、画像、動画、ニュース用が存在します。
その他には、ウェブクローリングを補完する目的で、
があります。
一方、APIや広告向けも存在し、
などが、日々、情報を収集してネット上を巡回しています。
これらを個別に理解する必要はありませんが、アクセス解析ログで、クロールの足跡だと認識できる程度には、頭に入れておくとよいです。
クローラーの役割は、ウェブページを巡回して情報を収集することは、すでに述べました。
ここでは、ウェブページの検出からインデックス登録までの一般的な流れについて説明します。
Google検索セントラル「JavaScript SEOの基本を理解する」では、非常にわかりやすく図解されており、イメージとして学習したい場合は最適です。
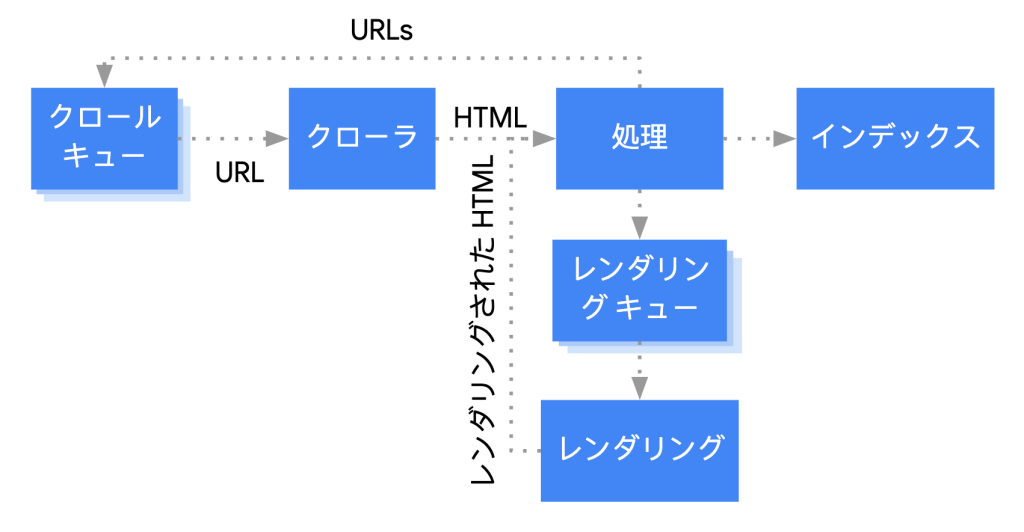
インターネットは常に新たなウェブページが公開され、既存のウェブページも更新されています。
ただし、その内容は即座に検索結果へ反映されず、クローラーがURLの検出や更新を把握してようやく情報収集を開始します。
クローラーによって得た情報をもとに、レンダリングというウェブページを視覚化して問題の有無を確認し、インデックス登録に値するかどうかが判断されます。
ここまでがURL検出からレンダリングまでの流れです。
前述のようにウェブページの内容を把握し、その情報を分析する作業を経て、Googleのデータベースに格納、いわゆるインデックス登録となります。
その目的は、クローラーが収集した情報を検索エンジンが利用できる形に整理、保存することです。
検索クエリを入力して、即座に関連性の高いウェブページが提示されるのは、インデックスされているからこそと言えます。
インデックスされやすいウェブサイトを目指すにあたっては、このプロセスの理解が非常に重要です。
クローラー対策とは、ウェブサイトを構成するウェブページが漏れなくクローラーに巡回され、情報収集されるよう手段を講じる取り組みで、インデックス登録のための最適化とも言えます。
SEO担当者の重要なタスクのひとつで、ウェブサイト構造の改善、適切なメタデータの使用、機能しないリンクの修正やリダイレクトの管理なども含まれます。
これらはクローラビリティ(後述)の向上に繋がり、最終的には検索エンジンの評価に大きく貢献する施策です。
ここでは、主なクローラー対策として、
について触れてみます。
Googleが提供している無料ツールでは、クローラーの巡回状況や、問題があるウェブページを特定が可能です。
それらの問題を解決するためには、Google Search Consoleが欠かせません。
その他、XMLサイトマップの送信、特定ページの手動でのインデックス登録リクエストを実行し、クローラーに効率の良い巡回とインデックスを促します。
XMLサイトマップとは、サイトの全ページのURLをリスト化し、クローラーの巡回をサポートする、XML形式のファイルです。
Google Search Consoleから、サイトマップのURLを送信することで、作業は終了します。
WordPressなどのCMS(コンテンツ・マネジメント・システム)を利用していれば、XMLサイトマップのファイル(sitemap.xml)は自動的に生成され、そのURLは、
https://www.my-blog.com/sitemap.xml (URLは架空)
となります。
もし自動生成されない場合は、サイトマップ生成ツールなどを使用し、ウェブサイトのルートディレクトリにアップロードする手間が加わります。
ちなみに、HTMLサイトマップと混同されやすく、
といった違いがあります。
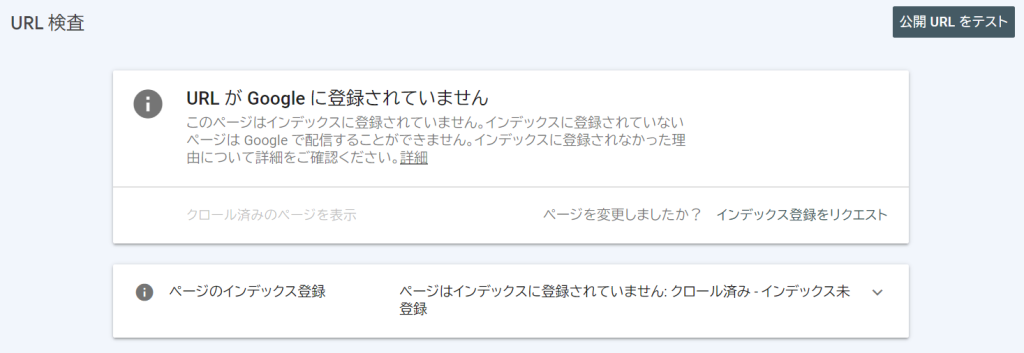
URL検査と呼ばれる機能を使用して、まず、特定のウェブページのインデックス状況を表示します。
インデックス登録されていない、あるいはウェブページを更新した場合は、インデックス登録をリクエストすることが常套手段です。
この手続きは、クローラーの巡回を促しますので、後日、インデックス状況を確認するようにします。
クローラビリティとは、クロールのしやすさを表す言葉で、検出からインデックスまでスムーズに行われることで、検索結果でのランキング向上に良い影響が得られます。
クローラビリティの向上策としては、さまざまな手段がある中で、
について少し詳しく解説します。
ページの表示速度は極めて重要な要素であり、ウェブページの表示の遅さは、ユーザーにとって最適化されているとは言い難く、クローラーのレンダリング(描画)にも影響します。
ウェブサイトに問題があれば、クローラーが十分に情報を収集しきれない可能性が高まり、コンテンツが正当に評価されない原因にもなります。
ページの表示速度については、Googleが提唱する Core Web Vitals(CWV:コア・ウェブ・バイタル)の3つの指標、
1. LCP(Largest Contentful Paint)
ページの主要なコンテンツの読み込み速度。2.5秒以内が目安。
2. FID(First Input Delay)
ユーザーの操作に対する反応速度。100ミリ秒未満が目安。
3. CLS(Cumulative Layout Shift)
ページの視覚的な安定性。スコア0.1未満が目安。
の理解と、数値のクリアが不可欠です。
クローラーはリンクを辿ってウェブページの情報を収集しますが、このプロセスを効率的に行うためには、各ページが他の関連するページと適切にリンクされていることが求められます。
関連性のあるページ同士がリンクされていると、クローラーはそれを高く評価し、結果としてウェブサイト全体のSEOスコアの向上に繋がります。
ユーザーにとっても必要な情報を見つけやすくなり、離脱率の低下も期待できるため、SEOの観点から見ても好ましい状況です。
内部リンク構造の最適化は、いわゆる「SEOに強いウェブサイト」にする上でも、欠かすことはできません。
ウェブページ間を移動する際のガイド、ユーザーに対して閲覧中のウェブページの階層ポジションを示すシステムが、パンくずリストです。
ナビゲーションの役割だけでなく、クローラーの階層構造理解にも大きな影響を与えます。
パンくずリストが機能しないウェブサイトは、クローラーがページ間の関連性を理解することが難しくなり、クローリングに差し支える可能性があります。
ユーザーの利便性とSEOの両面から、パンくずリストの導入は重要です。
ウェブサイトの構造は、ピラミッド型の三階層が理想とされています。
具体的には、トップレベルとなるホームページやメインカテゴリーページを頂点として、その下にサブカテゴリーや個々の記事ページが連なるように配置します。
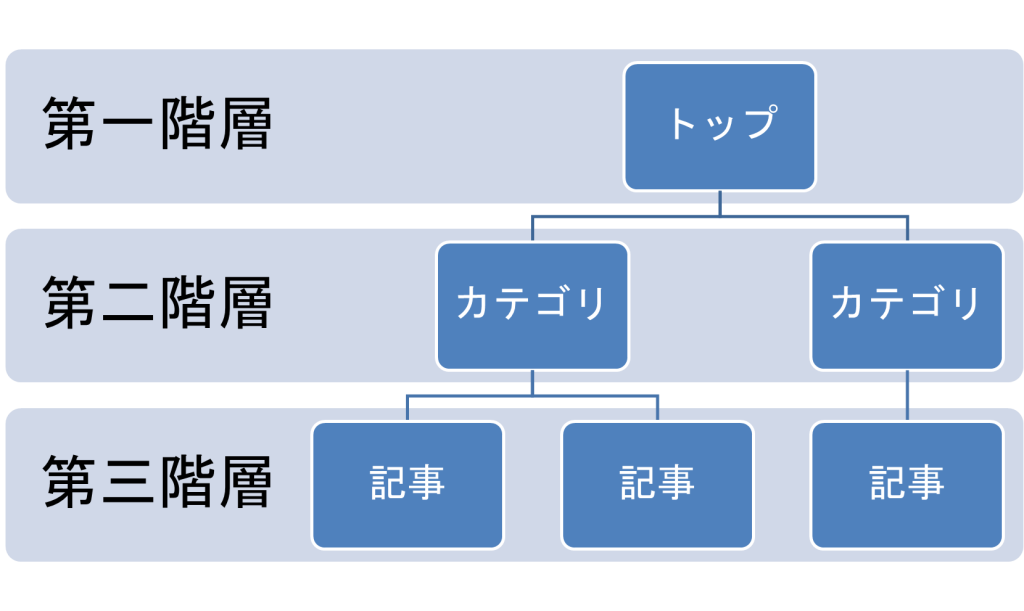
さらに横断的に関連するウェブページとリンクされていれば、クローラーは効率的に巡回し、インデックス登録にも効果的です。
ウェブサイトの規模にもよりますが、ピラミッド型の三階層を念頭に置いて、設計することが推奨されます。
ウェブサイトの中には、ユーザー情報を含む管理ページ、重複したブログ記事、会員登録やログイン画面など、検索対象にしたくないページがあります。
そのようなページに対しては、
の方法を用いて、クローラー巡回の制御が可能です。
ウェブサイトのルートディレクトリに配置する小さな容量のテキストファイルで、クローラーに対して、クロールの許可と回避を伝える役割を果たします。
具体的に、テキストファイルの内容を、参考例を用いて説明をします。

1.Googlebotに対して「/nogooglebot/」ディレクトリ以下のクロールを許可しない
2.全てのクローラーにサイト全体のクロールを許可
3.サイトマップファイルの場所
なお、サイト全体のクロールを許可する場合、2のような記述はなくても構いません。
そもそもクローラーは、巡回するようにプログラムされているからです。
命令を書くことが難しいと感じる場合は、robots.txtを生成するツールがありますので、それらを利用することをおすすめします。
robots.txtと並んで、利用頻度が高いのは「noindex」と「nofollow」タグによる制御です。
それぞれの目的は、
ことにあります。
noindexはインデックスを必要としないウェブページ、あるいはコンテンツの品質が低いウェブページなどに設定しますが、nofollowについては、信頼性の低いサイトへのリンク、ユーザーに価値を提供しないリンクを制御する際に有効です。
WordPressでは、ウェブサイト全体をインデックスさせない設定しか実装がなく、ウェブページ単位での設定に関しては、プラグインの導入、もしくは特定のテーマの使用などで対応することになります。

検索エンジンのクローラーの重要性とその役割、SEOにどのように影響を及ぼすかについて、基本的なことをお伝えしました。
クローラーを理解し、適切なクローラー対策を講じることで、ウェブサイトのクローラビリティを向上させることは、SEOの担当者に求められる施策のひとつです。
robots.txtの活用などを通じて、クローラーの動きをコントールすることは、SEOのパフォーマンスを大幅に向上させることにも繋がります。
もし、うまくインデックスできないという状況が長く続くようならば、もしかすると、今回のような基礎的な知識では対応できないこともあるため、お問合せから相談してください。